Citizen
Head of Internal Tools — Operating at every level simultaneously
My third week at Citizen, I watched Lily make an impossible choice.
3:47 PM. Someone hit "Go Live" in Brooklyn. A robbery happening. Right now.
3:47:08 PM. Lily had five seconds to decide: Does this stay live for hundreds of thousands of New Yorkers, or do we cut the feed?
Her hand hovered over the "BLOCK" button—steady, but she wasn't sure.
I recognized what I was watching. These were the underdogs keeping the whole operation running while everyone else focused on growth and features. They'd developed superhuman skills to do work that should have been impossible. And their tools kept failing them.
I've been that person. I wanted to give them better than I had.
The CEO's desk was right next to mine.
He was focused on growth, on the next big feature. Sometimes he'd forget why this internal work mattered—until an operator couldn't send an alert because the system crashed.
But I could bridge that gap.
Morning: strategic conversation with the CEO about scaling to new cities.
Afternoon: sitting with operators, headphones on, experiencing what it meant when audio clips piled up and the system froze. Understanding why a 30-second delay meant they'd lost track of which incident they were working on.
Next day: designing the solution, writing the code, deploying to production.
I was Head of Product for these internal tools and sole developer—product manager, designer, and coder all at once. Most people can do one or maybe two of these things. The job required all three simultaneously, operating at every level, translating between worlds that usually don't speak the same language.
The operators were skeptical at first. Understandably—they'd been burned by promises before. What changed their minds wasn't promises. It was showing up. Using their tools and feeling the same frustrations they felt every shift. Making them partners in solving their own problems.
Shadow the team, understand their needs, design something, build it, test it with them, repeat.
The Rebuild
It kept me up most nights. Not because of any single thing—everything, all at once.
Balancing thoughtfulness with velocity. Couldn't disrupt the operators or break the app that nearly 500,000 users depended on. But I needed to move fast enough that people felt progress.
New features required architectural understanding to roll out carefully. The CEO needed to see strategic value. The operators needed tools that actually worked. And I had to build it all as the sole developer while maintaining 24/7 operations.
Watching Lily's hand hover over that button, I had an insight: "real-time" to the user didn't have to mean "instantaneous" to moderation.
I brought this to the CEO. Explained how a 15-second buffer would reduce legal risk while improving operator decision-making. He bought it.
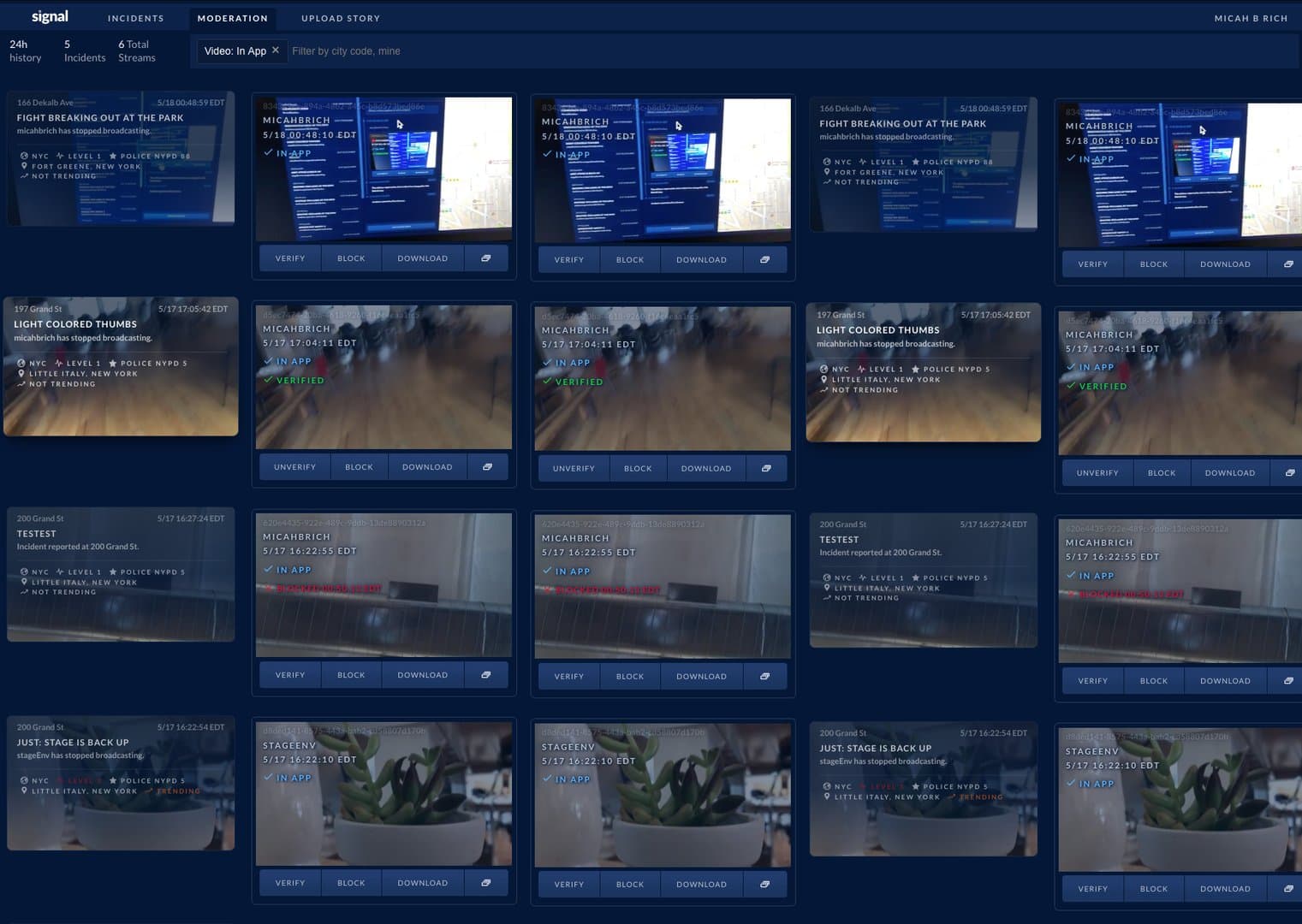
Then I sat with Lily. Walked through what the interface would look like. Grid showing multiple streams simultaneously. Full incident context right there. Reversible blocking so she could correct mistakes. Visual countdown showing exactly how much time remained. She told me what would actually work under pressure.
Then I built it. Designed the interface, wrote the code, deployed it to production.
A few months later, during a very public incident—someone threatening to jump—Lily had multiple live streams in her grid. The 15-second buffer gave her time to watch what was happening. The situation escalated. She saw it coming before users did. Blocked the stream just in time. The users never knew.
She'd made the right call at exactly the right time—calm, informed, confident.
That's what it looked like in practice. Strategic insight, operator partnership, technical execution. All three at once.
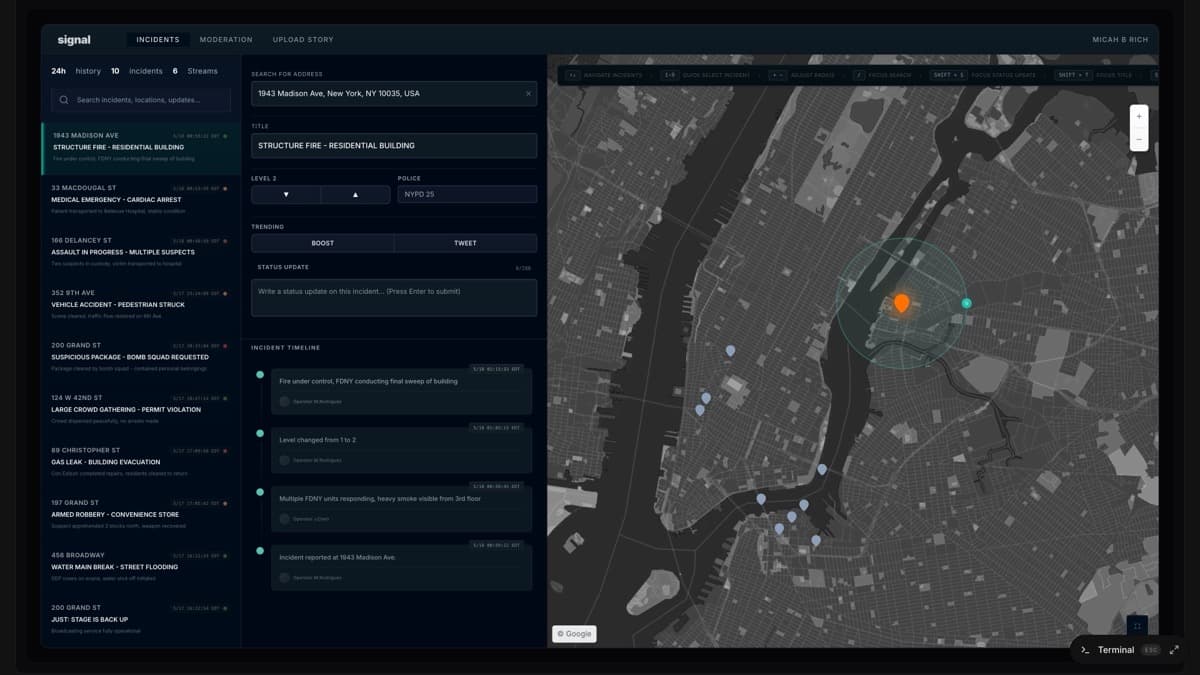
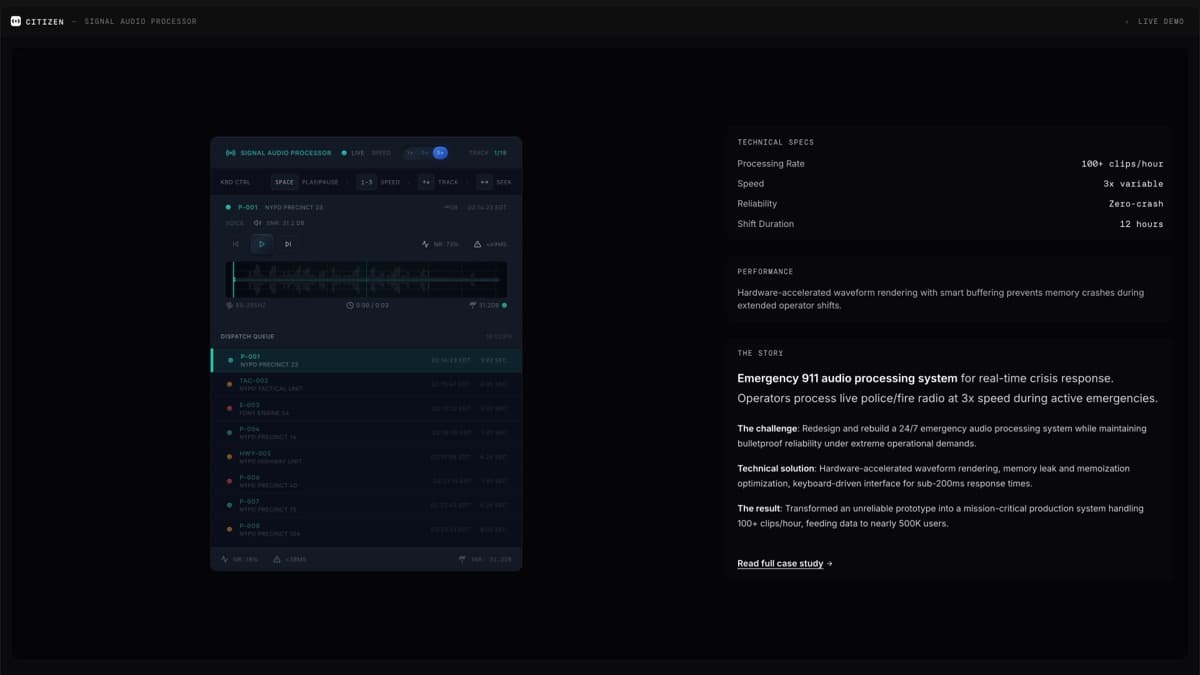
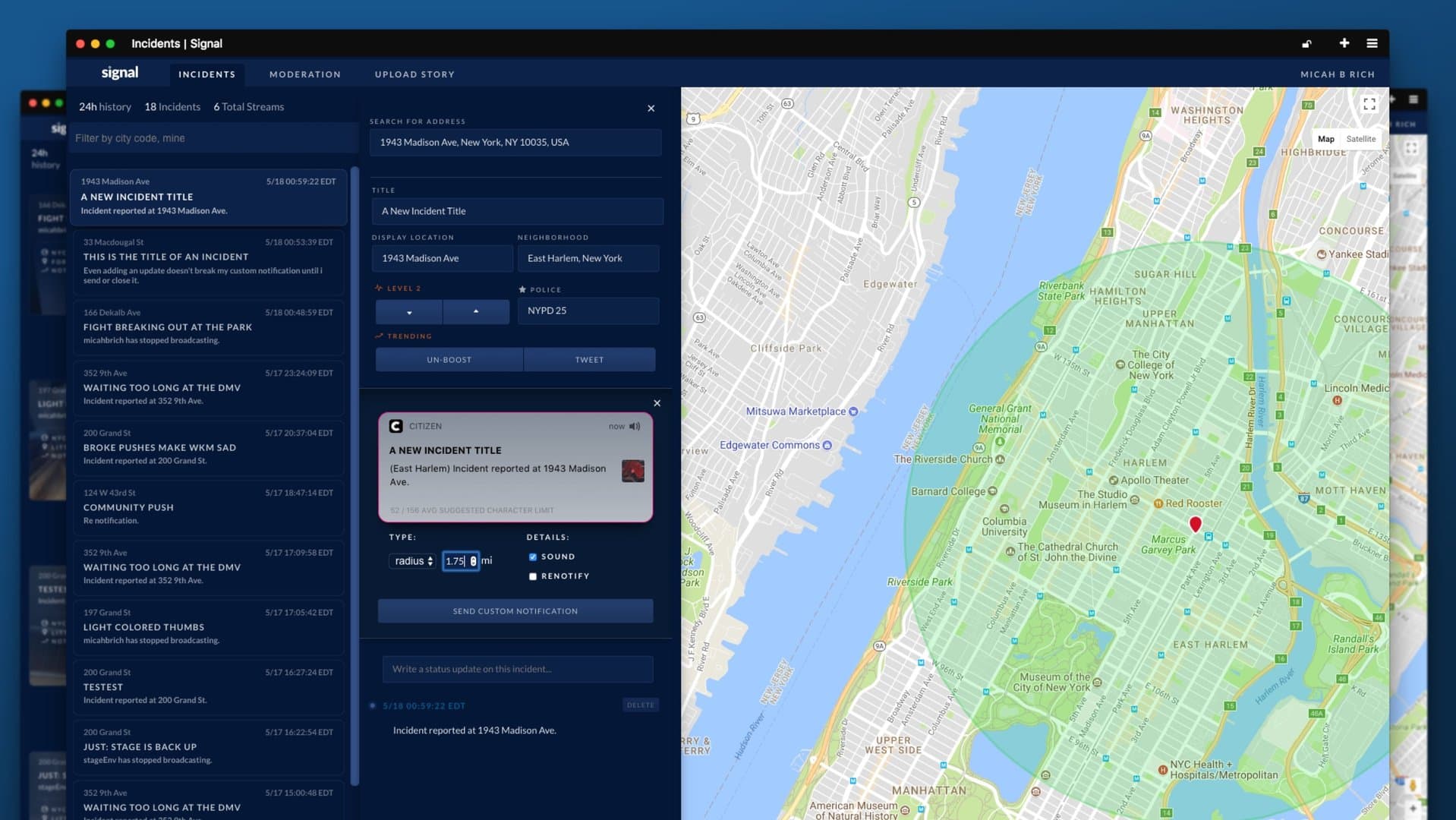
I rebuilt all three core systems the same way. Audio processing that could handle 100+ clips per hour at 3x speed without crashing. Real-time incident command center with live map overlays. Moved the entire stack from Create React App to Next.js, Firebase to Postgres, VPS to Vercel's global infrastructure.
When I introduced the Time to Incident metric to the CEO, he finally had visibility into what I'd been telling him mattered. Emergency response time improved 60%. Eight to twelve minutes down to three to five. Millions of people getting warned about nearby dangers 60% faster.
The operators who'd been labeled "behind" were suddenly performing at their natural, superhuman level. Sarah told me "reliability was a novelty"—just the fact that the system didn't crash felt remarkable.
They'd been capable of this excellence all along. They just needed tools that matched their capabilities.
Coming from agency work, I was used to building something, shipping it, and moving on. Get in, solve the problem, ship it, next project. Clean handoffs.
Citizen was different. This was staying with it month after month. Improving it continuously. Living with the consequences of my decisions and fixing what didn't work. Watching operators use the tools every day, seeing what worked and what didn't, iterating based on reality.
Most organizations split these worlds: strategists talk to executives, product people work with operators, engineers build the systems. The gaps between those worlds slow everything down. Misunderstandings compound. Good ideas die in translation.
The CEO would talk about scaling to new cities. I'd understand both why that mattered strategically and what it meant operationally—how many more clips per hour, what infrastructure changes it required, which operators could train new team members. Then I'd build the technical systems that made it possible.
That's what made the rebuild work. Not just having the skills, but being able to move between those worlds without friction. No handoffs, no translation layers, no waiting for someone else to understand.
The operators already cared deeply about their work. They just needed tools that matched that commitment.
Project Details
- Audio processing system — 100+ clips/hour at 3x speed, zero crashes
- Video moderation system — 15-second buffer innovation, grid-based workflow
- Incident reporting platform — real-time command center with live map
- Time to Incident (TTI) performance metric — 60% improvement
- Complete tech stack migration — Next.js, Postgres, Vercel infrastructure